StarGAN: Unified Generative Adversarial Networks for Multi-Domain Image-to-Image Translation
Summary
Although many GAN models show amazing performance in image-to-image translation tasks in recent studies, there are lots of limitations in scalability, robustness,efficiency and so on. Aimed at developing a more effective GAN model in image translation task, StarGAN is introduced to solve the problem that existing models are incapable of the implementation of multi-domain image translation among different datasets by using a single network. The StarGAN framework can learn mappings among multiple domains using a single generator and discriminator and behaves more effective than current similar models in the training phase. However, the other models cannot jointly train domains from various datasets, and if they want to learn all mappings within k domains, k(k-1) generators have to be trained, which is inefficient and ineffective.
The StarGAN model structure consists of two modules, including a generator and a discriminator. The working principle of StarGAN is to train a generator G that learns mappings among different domains and a discriminator D that distinguish between real and fake images and classify real images to its corresponding real domain. Basically, StarGAN adopts two generators (G1, G2) for generating near-true fake images to fool the discriminator, causing the discriminator to be unable to distinguish the authenticity of the images and classify the pictures as the target domain. The input of G1is an image and the target domain label, and then its output is a fake image. Furthermore, G2 tries to take in as input both fake image from the output of G1 and original domain under the depth-wise concatenation and reconstructs an image as the output that will be treated as the input image of G1.Therefore, a near-true fake image is generated after many generating cycles and inputs the discriminator for judgment.
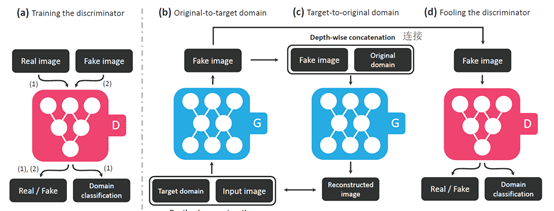
Toachieve the goal to train a single generator G that learns mappings among multiple domains, G is trained to translate an input image x into an output image yconditioned on the randomly generated target domain label c, G (x, c) → y.Meanwhile, an auxiliary classifier is introduced to permit a singlediscriminator to control multiple domains. The discriminator will produceprobability distributions over both sources and domain labels. That is D: x→{Dsrc(x), Dcls(x)}.Dsrc(x) means the probability distributionover sources given by D. The authorsdefine an adversarial loss to measure how easily the generated image iscorrectly distinguished:

Basedon the generated and adversarial characteristics, the generator will try tominimize the above objective, while the discriminator will try to maximize it.The loss function of the aforementioned auxiliary classifier can divide intotwo situations to discuss which is to classify real images and fake images tothe target domain c, defined as:
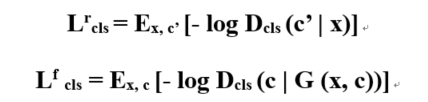
Toguarantee that translated images preserve the content of its input images whilechanging only the domain-related part of the inputs, a cycle consistency lossapplies to the generator, represented as:
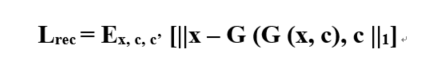
Insummary, the loss function of the full objective to optimize D and G is designed as follows:
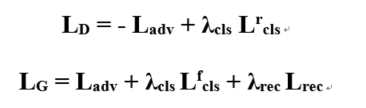
Thehyperparameter λcls, λrec is used to control therelative importance of domain classification and reconstruction loss. Both D and G will try to minimize the above full objective during the trainingprocessing.
Animportant advantage and novel aspect of StarGAN is that it can utilize severaldatasets with different types of labels while all existing models only can betrained with a single dataset. To alleviate the problem that label informationis partially known to each dataset, the authors introduce a method named maskvector m to ignore unspecified labelsand focus on the explicitly known label provided by a particular dataset. Themask vector m is represented by ann-dimensional one-hot vector, where n stands for the number of datasets.Therefore, a unified version of the label is made as a vector c(~):
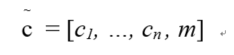
Where ci represents the label of ith dataset. So it solves theproblem of the inconsistent labels on multiple datasets and inability to sharethe label and transfer the feature. When training StarGAN with multipledatasets, the domain label c(~) is applied and the model isto be trained in a multi-task learning setting, where the discriminator triesto minimize only the classification error associated to the known label.
Beforestarting to implement the model, we should understand the internal constructionof the generator and discriminator. The generator network structure of StarGANis modified and adapted from CycleGAN, composing of two convolutional layerswith the stride size of two for downsampling, six residual blocks, and twotransposed convolutional layers with the stride size of two for upsampling.Moreover, it applies the instance normalization method for the generator butnot for the discriminator. Adapted from PatchGANs, the discriminator isdesigned to classify whether the local image patches are real or fake.
The twodatasets CelebA and RaFD are used to train and test StarGAN, and try to makethe comparison between StarGAN and some baseline models like DIAT, cycleGAN,and IcGAN, finding the advantage and strength of StarGAN. The qualitativeresults on CelebA show a higher visual quality and preserve the facial identityfeature of an input. Moreover, quantitative result reflects that StarGANobtained the majority of votes for best transferring attributes in all cases.As for the result on RaFD, StarGAN is capable of generating the mostnatural-looking expressions and preserve the personal identity and facialfeatures of the input. Furthermore, the model gets the lowest classificationerror, meaning producing the most realistic facial expression. Also, theparameters required of the model is less than other models, enhancing thescalability of the model. When training model jointly on CelebA and RaFD, ithas confirmed that StarGAN can properly learn features in a dataset andtransfer them to another dataset by using a proper mask vector, achievingexcellent results on image-to-image cross-domain translation.
Due tothe limited number of test datasets used in the experiment, it is almost notpossible to verify whether the StarGAN model is universal or not. Anotherunfortunate fact is that some properties outside the target domain arefrequently modified. For instance, face attributes would be easily modifiedwhen executing the synthetic facial expression task. For further development ofthis model, we assume that the model will develop towards more accurate andfine-grained target domain generation, and meanwhile ensure the stability of non-targetdomain attributes. However, it also is worthy of recognition that this modelhas achieved relatively excellent improvement and progress on the efficiencyand quality of the image-to-image translation. In particular, the beginning oftraining models with multiple different datasets with various labels created.It is valuable work to enable more researchers to explore and develop excellentimage translation applications across multiple domains.
Appendix
[1] StarGAN: Unified Generative Adversarial Networks forMulti-Domain Image-to-Image Translation Yunjey Choi 1,2, Minje Choi 1,2, MunyoungKim 2,3, Jung-Woo Ha 2, Sung Kim 2,4, and JaegulChoo 1,2 1 Korea University, 2 Clova AI Research (NAVER Corp.), 3 The College of NewJersey, 4 HKUST IEEEConference on Computer Vision and Pattern Recognition (CVPR), 2018 (Oral)
[2] The code of this paper is open in Github.
[5] Facial Attribute Transferon CelebA
[6] Facial ExpressionSynthesis on RaFD

